Deciphering SEDA IVMs - A Verification Specialist

Special Thanks to
Matt, Peter, Jasper and Mario from SEDA team for a detailed review & feedback on the articles.
In the first part of this article, I made some strong arguments on:
- the shift toward modular stacks,
- how modularization creates specialists,
- the rise of Verification marketplaces and verification specialists,
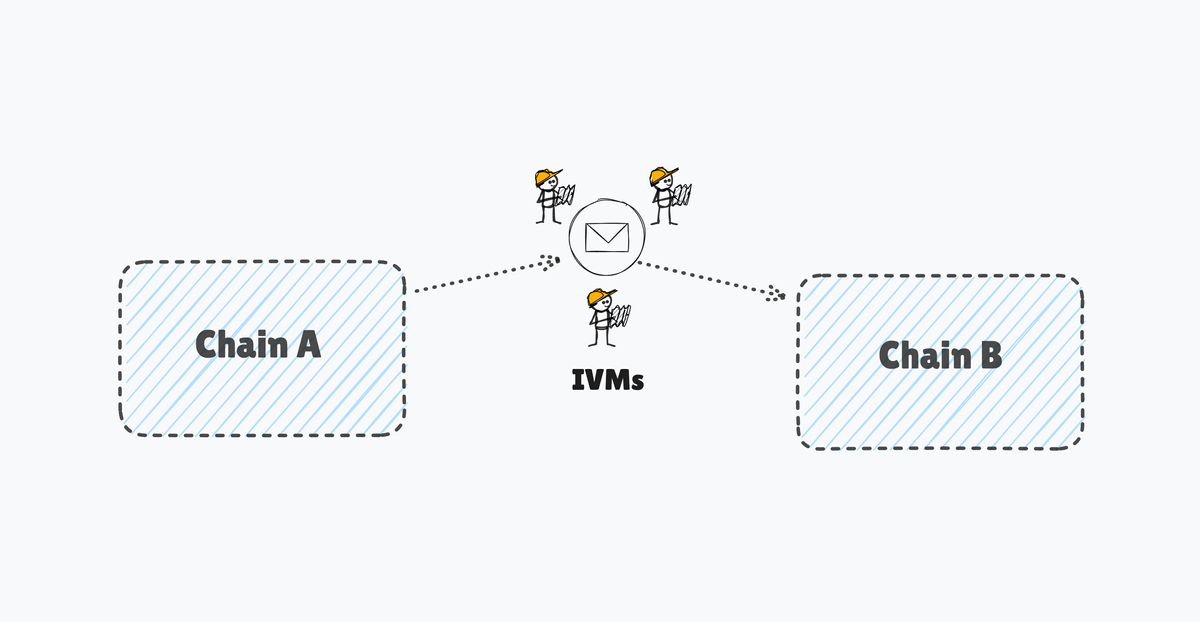
In this article, we will explore an emerging verification specialist in the modular interop era, i.e., SEDA IVM.
We will deep-dive into:
- what exactly is IVM,
- core components of IVM,
- how these components work together
- and, most importantly, what makes IVM unique
Buckle up Decipherers, and let's first start with our usual 100-word definition.
SEDA IVM in 100 words
SEDA’s Interoperability Verification Module (IVM) is a decentralized, programmable verification framework that is designed to offer customized oracle programs that can enable verification across all VMs to provide secure and specialized inter-chain communication.
Unlike traditional verification models (eg multi-sigs or centralized relayers), IVMs provide a modular, plug-and-play system where any interoperability protocol, intent-based bridge, or chain abstraction layer can integrate permissionless and cryptographically secure verification.
Each IVM runs on SEDA’s Programmable Oracle Infrastructure, allowing custom verification rules for different networks, RPC endpoints, and security settings.
Most importantly, IVM ensures that state verification happens in a tamper-resistant and decentralized manner.
We now have a basic definition of IVMs but there are quite a few things to unpack.
To understand these properties and how they work:
- let’s first understand the core components that are involved
- and then how all of them combine and work together
Core Components of IVM
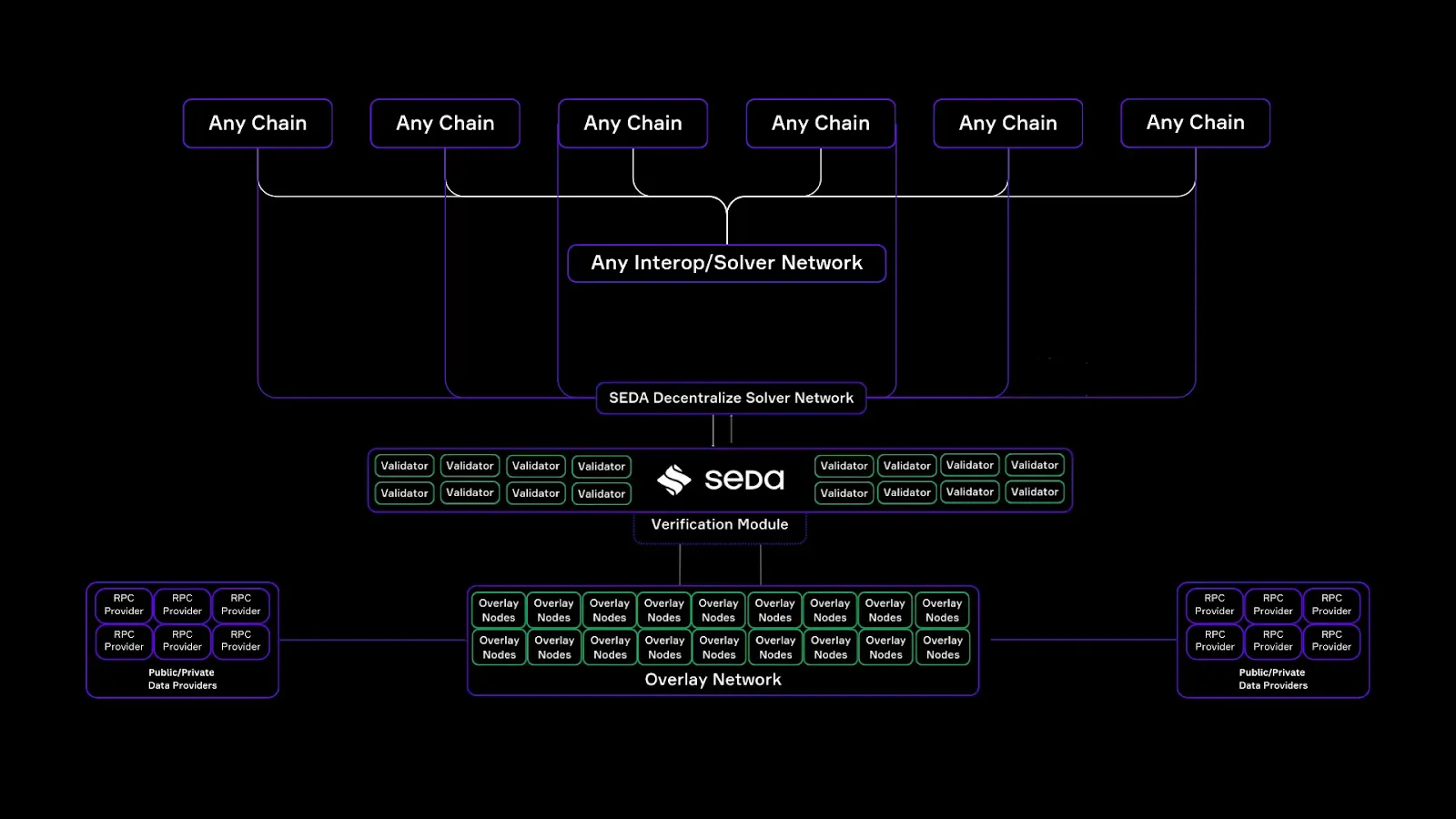
- The Module: At the foundation of the SEDA IVM lies the Oracle Program, which serves as the programmable logic layer for defining how verification operates. This enables developers to define their own verification rules, data sources, and processing logic.
- Decentralized Solver Network: This acts as the communication layer between SEDA and all connected blockchain networks where a prover contract is deployed.
- The Prover Contracts: The prover contracts are the final integration point where verification results are parsed and validated on the destination chain. It is a universal verification contract that can be deployed in any blockchain.
Additionally, prover contracts standardize the verification process across all chains, eliminating the need for interop protocols to build custom validation logic for each network. - Independent Overlay Network: Consider this as the core attestation layer responsible for verifying the on-chain state. It consists of thousands of independent nodes that operate in a decentralized and permissionless manner.
- RPC Data Providers: Reliable state verification requires access to accurate, up-to-date data from different blockchain networks. SEDA is designed to connect to both public and private RPC endpoints, ensuring that IVMs can access high-quality state data from multiple sources.
- The SEDA Main Chain: The SEDA Main Chain acts as the final verification layer, where all verification results are aggregated, cryptographically signed, and stored.
We will read more about this in next sections.
Let’s now understand how all of these components fit together.
Lifecycle of a Data Request in SEDA IVM
The best way to grasp how all of these components fit together is to go through a complete lifecycle of a Data Request in the IVMs.
Step 1: Triggering a Verification Request
The verification lifecycle begins when an event on the source chain requires cross-chain validation, such as a bridge deposit, an intent-based transaction, or an interoperability protocol triggering validation before execution.
- The user submits a request via
SedaCoreV1::postRequest. - Request details and fees are stored on the contract.
- A unique
request IDis generated and added to the pending request queue.
At this stage, the verification request is structured, recorded, and prepared for off-chain processing.
Step 2: Off-Chain Processing by SEDA IVM
- Solver Network Detects the Request
- A single solver from within the decentralized solver network detects the verification request and forwards it to the SEDA Network.
- The request contains metadata, event details, and the relevant contract states required for validation.
- Request Forwarded to Overlay Node Network
- The request then moves to the overlay nodes, where a secret committee of randomly selected Overlay Nodes is formed to perform the actual verification. This randomization is done using a Verifiable Random Function (RFC 9381)
- Overlay Nodes Query the Source Chain
- The selected Overlay Nodes query the predefined RPC endpoints ( as per the IVM configuration settings) and retrieve the necessary data from the source blockchain.
- Commit-Reveal Scheme for Secure Data Attestation
- Each Overlay Node initially commits its computed result in an encrypted form, preventing premature data exposure that could allow adversarial manipulation.
- Only after all commitments are submitted do they reveal their results simultaneously.
- Data Processing & Filtering by DR Tally
- The results undergo data filtering, aggregation, and cleaning by the Data Request (DR) Tally function.
- The DR Tally follows the IVM’s predefined instructions, ensuring that only valid, non-conflicting results are passed forward.
- This step has 2 important phases:
- The Execution Phase, run by Overlay Nodes, fetches and processes data from multiple external sources. Since network requests and data sources may vary, this phase is non-deterministic.
- The Tally Phase, run by SEDA Chain Validators, processes execution results in a deterministic manner. It aggregates multiple execution reports, applies tally instructions, and ensures consensus at the chain level.
For the Curios Minds: Execution & Tally Phases 👇
The distinction between the Execution Phase and Tally Phase plays a crucial role in ensuring security and reliability within SEDA’s verification model:
- Non-Deterministic vs Deterministic Processing:
- The Execution Phase involves fetching off-chain data, making it non-deterministic due to variations in data availability and sources.
- The Tally Phase is fully deterministic, as it operates on predefined tally instructions and execution reports, ensuring that all validators reach the same result.
- Preventing Data Manipulation:
- Since execution interacts with external sources, data integrity is maintained through cryptographic commitments and redundancy in Overlay Nodes.
- The tally phase eliminates subjectivity by enforcing deterministic consensus, ensuring that only validated results make it on-chain.
- Consensus Reliability:
- Because the tally phase is executed by all main chain validators, it ensures that data aggregation is verifiable and cannot be manipulated.
- This prevents scenarios where malicious nodes could influence data at the execution level.
At this stage, SEDA has collected, verified, and processed the data request without any single point of failure, and the verified data is now ready for cryptographic signing.
Step 3: Batch Submission & Cryptographic Proof Generation
Once the Overlay Nodes reach consensus, the verification result is prepared for submission to the destination chain.
- SEDA Main Chain Aggregates and Batches the Verified Data
- The final aggregated verification result is batched to improve efficiency. A batch contains multiple verified requests, optimizing gas costs.
- Validators on SEDA Chain Sign the Batch
- The SEDA Main Chain applies cryptographic signatures using PoS validators, ensuring that the proof of verification is tamper-resistant and verifiable on-chain.
- The signed batch is then stored on the SEDA Chain, making it immutable and auditable.
- The Solver Retrieves the Signed Batch
- A Solver fetches the batch from the SEDA Main Chain along with cryptographic proofs and prepares it for submission to the Prover Contract on the destination chain.
- Signed Batch is Submitted to the Prover Contract
- The Solver submits the signed batch via Secp256k1ProverV1::postBatch.
- This batch contains:
- A results root ( i.e., merkle root of the results )
- A validator root ( i.e., merkle root of the validator set )
- When submitting a batch, the solver also provides:
- Batch signatures from validators
- Merkle proofs verifying the inclusion of the validator’s public keys in the validator tree.
- These proofs ensure that the signatures originate from validators listed in the most recent validator set known by the Prover Contract.
At this stage, the verification proof is finalized and is ready to be validated on the destination blockchain.
Step 4: Result Verification on the Destination Chain
After the verified proof reaches the destination chain, the Prover Contract ensures its authenticity before the final transaction is executed.
- Prover Contract Parses the Proof
- The Prover Contract on the destination chain receives the proof from the Solver.
- It then parses the proof and prepares it for validation.
- Cryptographic Verification of the Proof
- The proof is verified using SEDA’s secp256k1-based cryptographic validation via
Secp256k1ProverV1::verifyResultProof. - The verification ensures the proof is included in the signed batch stored on the SEDA Main Chain.
- The proof is verified using SEDA’s secp256k1-based cryptographic validation via
- Successful Verification Triggers Fee Distribution
- Once the proof is validated, fees are distributed to the relevant network participants based on SEDA’s three-tier fee model.
At this stage, the verification request has been fully authenticated, and the system is ready to process the final cross-chain execution.
Step 5: Final Request Completion & State Change on Destination Chain
Once verification is completed, the destination contract processes the final state transition.
- Prover Contract Confirms the Verification to the Destination Contract
- The destination smart contract receives the confirmation from the Prover Contract that the proof is valid.
- Cross-Chain Transaction is Executed
- Once the proof is validated, the cross-chain transaction relying on this proof can be executed. For instance:
- If the proof was to verify a cross-chain funds movement, the funds are released to the user on the destination chain.
- If the proof was to verify an intent-based action, the execution proceeds on the destination protocol.
- Once the proof is validated, the cross-chain transaction relying on this proof can be executed. For instance:
- Pending Request is Marked as Completed
- The
request IDis then removed from the pending queue on the network. - Events are emitted on-chain, providing a verifiable record of the verification.
- The
And Voilaaaaa. 🎉
This completes the entire lifecycle of verification, and the secure execution of the cross-chain transaction using the SEDA IVM.
Is SEDA's IVM just another Verification Mechanism?
At this point, it's natural to ask: How is this different from existing solutions?
During my research, I’ve identified a few key aspects that make SEDA IVMs unique, specialized, and better at addressing the challenges of modular cross-chain interoperability.
To fully grasp how SEDA IVMs differ from other verification models, we will analyze its characteristics across the following critical aspects:
- The Security Aspect
- The Liveness Aspect
- The Permissionless Programmability Aspect
- The Modular Flexibility Aspect
1. The Security Aspect
One of the best ways to evaluate an oracle’s strength is to evaluate its security aspects.
Let’s understand how secure IVMs are:
1.1 Mitigation of Collusion Risk
One of the biggest vulnerabilities in multi-signature (multi-sig) models is the risk of collusion among signers.
There are two critical reasons behind this risk:
- In most multi-sig setups (e.g., 3-of-5 or 4-of-7 configs), attackers only need to compromise a few private keys to take over verification. Once the threshold is reached, the entire system is compromised, allowing unauthorized cross-chain transactions.
- Many interop protocols still control their multi-sig verification stacks, meaning users trust a small group of actors. If signers collude (or get bribed), they can fake verification proofs and trigger unauthorized transfers on target chains.
However, SEDA mitigates such collusions to a great extent.
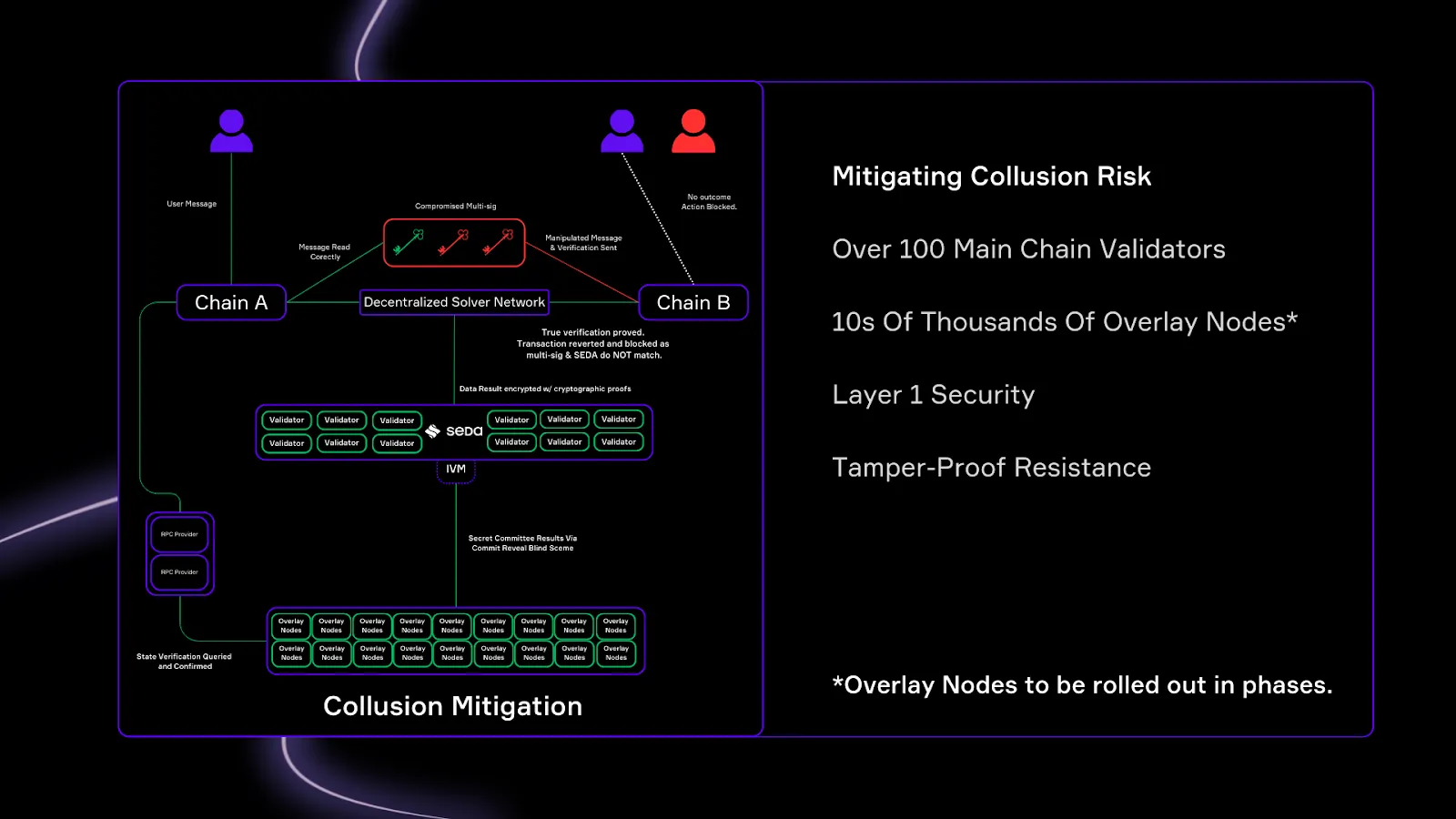
- Proof-of-Stake Secured Validation
- Unlike multi-sigs, the SEDA IVM inherits security from the SEDA Main Chain, which is secured by a Proof-of-Stake (PoS) consensus model.
- Instead of trusting a small group of private key holders, security is anchored to a decentralized network of validators. This means manipulating verification would require a 66% attack on the entire SEDA Chain, an exponentially harder task than bribing a handful of multi-sig signers.
- Decentralized Solver & Overlay Networks
- The IVM verification doesn’t rely on a fixed set of validators—instead, it uses a dynamic, permissionless network of:
- Solvers - who monitor prover contracts and submit verification requests.
- Overlay Nodes - who form randomized "secret committees" to validate the state
- The IVM verification doesn’t rely on a fixed set of validators—instead, it uses a dynamic, permissionless network of:
- Mandatory On-Chain Signature from SEDA Validators:
- All verification proofs generated within SEDA IVMs must be cryptographically signed by the SEDA Main Chain’s validator set before submission.
- This ensures that even if a malicious relayer attempts to forge verification results, the proof will be rejected at the contract level since it lacks a valid PoS-backed signature.
1.2 Elimination of Fragmented Verification Stacks
Another major challenge in traditional cross-chain verification is the fragmentation of security zones.
This means:
- Each new route requires a new verification stack
- Custom multi-sig models require a different validator set for each chain pairing (e.g., Ethereum ↔ Solana, Solana ↔ Avalanche). As a result, protocols must maintain multiple security zones with different verifier combinations.
- Verification Fragmentation Makes Scaling Hard.
- Some interoperability providers offer third-party multi-sig verifiers, allowing developers to combine multiple providers to verify cross-chain messages.
- However, not all verifiers support every blockchain, meaning interop protocols must mix and match different verifiers across different routes, leading to security inconsistencies.
SEDA’s IVM resolves this fragmentation with Single Security Zones.
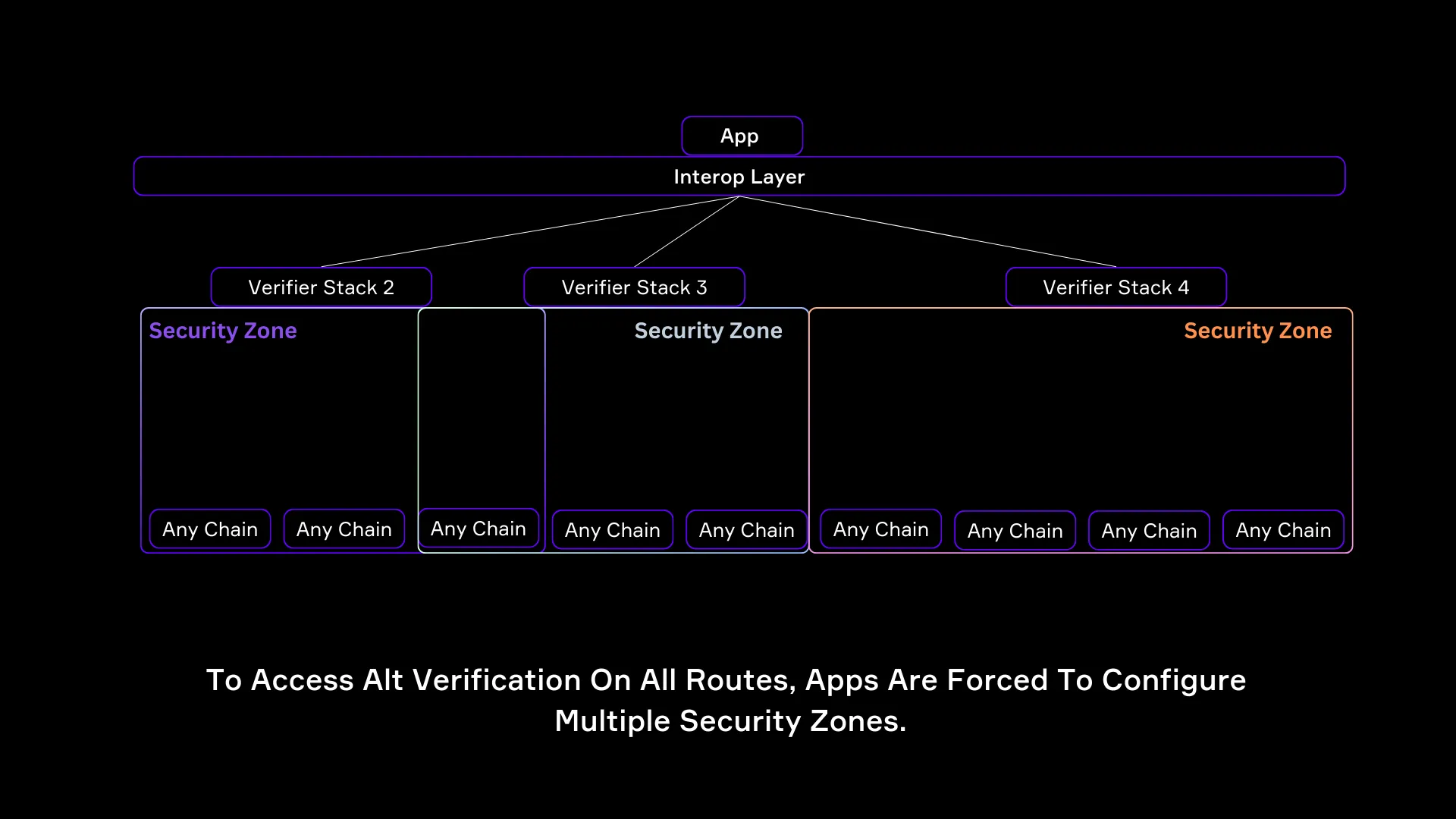
- One Security Zone for All Chains & All Routes
- SEDA IVM establishes a single, unified security zone. This means wherever a Prover Contract is deployed, verification becomes available, without the need to reconfigure multiple security zones for each new integration.
- Permissionless Prover Contracts Create a Standardized Security Layer
- Once a chain has a Prover Contract deployed, SEDA proofs are valid across all interop protocols using IVMs, creating a single standardized verification framework for all networks.
Note: As of now, Prover Contracts are designed for EVM-compatible chains. Expanding to non-evm chains is a future feature and is part of the SEDA team’s roadmap.
1.3 Implementation of Cryptographic Tamper Resistance
An interesting finding was how SEDA’s Main Chain implements a cryptographic tamper resistance to avoid this issue:
- Tamper-Resistant Proof Aggregation via SEDA Main Chain
- SEDA’s Main Chain acts as the final arbiter of verification correctness, ensuring that only cryptographically signed proofs are accepted. This means all verification results must be signed by PoS validators before being relayed, preventing fraudulent modifications by relayers.
- Commit-Reveal Scheme discourages Data Manipulation
- Overlay Nodes commit to their results first before revealing them, preventing them from strategically altering their responses based on others’ submissions.
2. The Liveness Aspect
An overlooked yet critical aspect of cross-chain verification is liveness—the ability of a system to continuously operate, even in the face of node failures, congestion, or unexpected disruptions.
While many traditional verification models suffer from downtime risks, here is how the SEDA IVM aims to ensure continuous liveness guarantees:
2.1 Distributed Verification: No Single Point of Failure
Unlike multi-sigs or centralized relayers, the SEDA IVM distributes verification across multiple independent components:
- Proof-of-Stake (PoS) Secured Main Chain:
- The SEDA Main Chain is secured by over 100 validators, ensuring consensus and data integrity. If a portion of validators experience downtime, the remaining active validators continue processing verification proofs, preventing network-wide failure.
- Overlay Network with Thousands of Nodes:
- The Overlay Network consists of thousands of independent nodes, responsible for fetching, processing, and validating off-chain data.
- If some Overlay Nodes go offline, the distributed model ensures other nodes automatically step in to maintain seamless verification.
Liveness risks are significantly mitigated as SEDA operates with over 100 main chain validators and thousands of overlay nodes.
3. The Permissionless & Programmability Aspect
Another standout feature that is super interesting to me as a developer is its programmable verification framework.
Unlike rigid security models that dictate how verification must be performed, SEDA IVMs offer full configurability, enabling protocols to:
- Define verification routes by specifying the chains and transactions that require validation.
- Select and modify data sources by choosing which RPC endpoints, APIs, or validators participate in the verification process.
- Upgrade modules seamlessly, allowing interoperability providers to add support for new chains and tokens without overhauling their verification stack.
- Customize aggregation and filtering logic to ensure only the most relevant, accurate data is used for verification.
- Set replication factors for Overlay Node secret committees, balancing decentralization, cost, and efficiency.
This high degree of programmability makes IVMs a flexible and future-proof verification layer, ensuring compatibility with any virtual machine, bridge, or interoperability model.
Let me explain this with an example of Replication Factors.
In most multi-signature verification setups, protocols operate within fixed security parameters, relying on a small validator set (e.g., 2-of-3 or 4-of-7 configurations). These limited signer groups introduce centralization risks and create a static verification model that cannot scale efficiently.
IVM removes this limitation by introducing a programmable replication factor, allowing protocols to:
- Dynamically adjust the number of Overlay Nodes in an execution committee
- Increase decentralization for high-value transactions by requiring larger committees to sign off on verification results.
- Optimize for cost and efficiency by reducing committee size for lower-risk transactions.
This ability to fine-tune decentralization makes the SEDA IVM a highly flexible verification system, ensuring that protocols can adapt their security model as network demands evolve.
And then, It's Permissionless.
The SEDA IVM is entirely permissionless, ensuring any protocol, chain, or interop provider can integrate its verification layer without approval or reliance on a central authority.
Its open-source SDKs further democratize access, reducing development barriers and allowing teams to experiment, integrate, and iterate without restrictions.
I will write a dedicated developer guide on how to easily integrate the SEDA IVM in their stack. Soon anon.
4. The Modular Flexibility Aspect
The SEDA IVM is not a standalone verification module—it is a highly adaptable system that integrates seamlessly across diverse blockchain environments.
This means:
- Verification logic is chain-agnostic.
- Off-chain agents can directly trigger data requests, opening up new verification architectures where external actors can submit requests to SEDA and receive batched proofs on their preferred chain.
- Data is portable across verification layers – Once a verification result is processed on the SEDA Main Chain, it can be batched, signed, and forwarded to any network where a Prover Contract exists.
This level of flexibility means SEDA IVMs are not confined to a specific verification approach, chain, or interop framework—it is an interoperability-agnostic system that can support any verification requirement while scaling with the evolving demands of apps.
Wrapping it UP
As the industry moves toward modular interoperability, the demand for specialized verification providers is growing, ensuring that applications can choose security models tailored to their needs.
We are already seeing the rise of verification specialists, each addressing different trade-offs between security, speed, decentralization, and cost. As cross-chain ecosystems scale, verification will continue to fragment into specialized, competitive markets, ensuring that interoperability isn’t just faster, but fundamentally more secure and trust-minimized.
As a builder/protocol, it's now easier than ever to customize the right verification schemes that suit your use cases – instead of relying on default verification techniques. ( no more multi-sigs-based verifications plz ).
I will continue to write more on how to learn, improve, and integrate these modular pieces into your stack.
Till then, have a great time.
Cheers, Decipherers.


![Why Learn Hard Solidity Things [ ABI Encoding Series: Part 0 ]](/content/images/size/w600/2025/06/ChatGPT-Image-Jun-8--2025--07_07_45-PM.png)